|
Backward Chaining enables the decomposition of
complex problems into smaller modules. By starting with highest-level
description that solves the problem, this quickly leads to the creation
of a working system. If the questions asked by the system are not
at the appropriate level for the intended end user, adding additional
rules enables deriving the information using simpler questions.
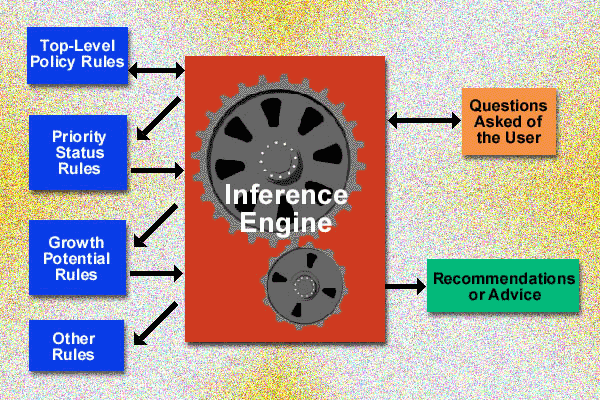
Figure 1 shows the rules in the system and how individual
rules call other blocks of rules.
A system can be started with high level rules describing
the decision-making process and expanded to whatever level is required
by adding blocks of rules that cover specific decision details.
The system can reuse rule blocks in multiple places. For
example, if another part of the system must know if a customer should
receive priority service, perhaps to determine what method to use
for product shipments, the inference engine automatically invokes
the same rule block to derive the value.
In the future, if there are other criteria to determine if
a customer is a "priority customer", simply add another
rule. The inference engine automatically calls and tests this new
rule in any relevant situation, making it very easy to add rules and
expand a system.
Comparison of Inference Engines to Traditional
Programming
A backward chaining inference engine makes system
development and maintenance much easier. When first exposed to IF/THEN
rule logic, they are often confused with the simple IF/THEN statements
of computer languages such as C and BASIC. However, the inference
engine is fundamentally very different and much more powerful.
A BASIC program, for example, allows nested
IF/THEN blocks. However, if a program needs to reuse a complex or
deeply nested IF/THEN relationship in another section of the program,
it must duplicate the code, or make it a function that is explicitly
called. A standard program will not simply call the necessary section
of computer code just because it exists in the system - yet this is
exactly what the inference engine does.
During backward chaining, if any rule assigns
a value
to variable X, that rule is automatically available whenever other
rules being tested need a value for X. Rules can be physically located
anywhere in the system, and there is no explicit linking of rules.
Having two rules use the same variable is all that the inference engine
needs to link them. |
|
This rather free-form nature of rules makes develop
ment very simple. Provide the IF/THEN rules necessary to make a decision
and tell the system what to derive, and the inference engine does
the rest. The engine asks the questions in a focused manner, and only
asks the relevant questions that it cannot derive from other rules.
It does not ask unnecessary questions as often seen in traditional
programming.
Programmers might look at the IF/THEN rules in a
simple system, such as those demonstrating the above concepts, and
feel they could program a similar system in a few lines of Visual
Basic. For very simple systems, that is true. However, if the system
grows even a modest amount, the problem rapidly becomes very complex
to program using traditional techniques. It requires far more than
just nested IF/THEN statements to handle cases where there are multiple
sources to derive a fact,
multiple uses of the same rules,
many levels of derivation that may depend dynamically on user input.
Traditional code rapidly becomes very complicated when
handling any of these situations. It becomes even more complex when
adding new rules and maintaining the system. Adding a single new rule
can have ripple effects across the entire system and this is considerably
more complex when the programmer has not seen the code for a while
or someone other than the original programmer is maintaining it. Implementing
a new heuristic using traditional programming is often quite difficult
and if not added correctly, often has side effects that are difficult
to detect and fix.
For significantly complex systems, the most efficient
approach is separating the rules from the actual program code and
handling the rules more as data. By writing a program to process the
rules as data, this allows changing the rules without changing this
program. Changes to the program that processes the rules do not necessarily
affect the rules and changes to the rules usually do not affect the
program. This partitions the data from the program and greatly reduces
the effects of changes in one on the other and the corresponding testing
when there are rule changes. This is, in effect, an Inference Engine
- though perhaps not a full featured one.
Working with an existing inference engine is far easier
and much more productive. Using a proven inference engine that has
already been tested and should be relative error free is similar to
using a well-utilized programming library. Programmer benefits from
the testing done by those that have already worked with the inference
engine on previous projects.
|