| historical student test
records such as how each student answered each question and the score
awarded can be used to generate decision trees for determining an
optimal question sequence for profiling a successful or unsuccessful
student. In these tests, one uses a database of test information to
determine decision trees to drive other tests. With this technique,
the system identifies successful students with a small fraction of
the questions given on the original test. Students that passed the
test answered a subset of the questions the same, and students that
failed, answered a small subset of the questions the same. Some questions
do not influence whether the student passed or failed so it is possible
to cull out these questions and make the test more efficient. The
simplest case is when almost everyone answered them correctly, or
almost everyone answered them wrong.
Automatic Generation of Decision Trees from Test
Scores
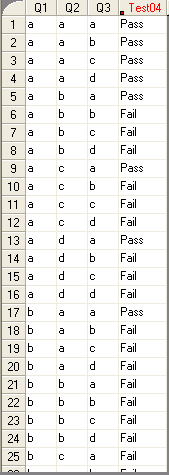
Following is a very simple example with hypothetical
test scores that represent a simplistic Pass/Fail three-question test
taken by 64 students (see Figure 4). A real test would probably use
scores ranging from 0 to 100% and have many more questions.
|
|
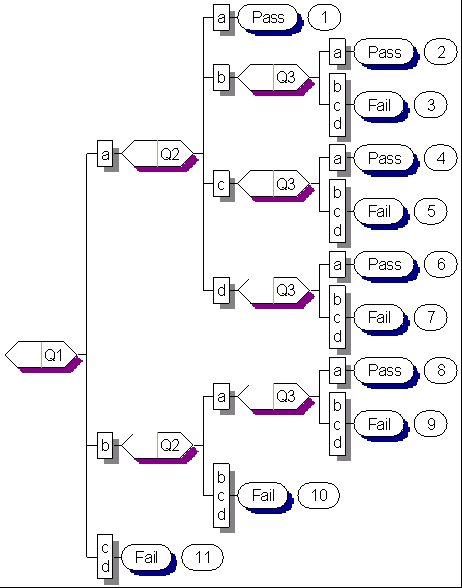
Here is the resulting decision tree, drawn by the
Knowledge Builder system using its automatic inductive knowledge acquisition
facility, and not drawn by a developer.
This also helps with a perennial issue in multiple choice
testing: students who guess. After all, in a four-answer test protocol,
students are likely to be correct 25% of the time. A simple approach,
recommended by many testing authorities, is to use five or more distracters.
On a more individual level, you simply throw out tests that have very
low scores. The knowledge based induction engine helps with this in
generating a decision tree by effectively ignoring or grouping all
such low scorers and other outliers. Also, as the student's score
is being monitored continuously as the test proceeds, it is possible
to include specific question groups that assess whether or not extensive
guessing is occurring.
Notice that every student that answered Q1 with 'c' or
'd' failed the test. Therefore, if this tree were to drive an adaptive
test, then the students that answered Q1 with 'c' or 'd' would fail
the test immediately, and not see any other questions. This is extremely
efficient! In a real situation, this usually happens after answering
approximately 20% of the test questions. The current student's profile
fits a failing student's profile as determined from past test records.
Notice that Q3 is never asked to pass a student if |