paraphrase identification.
This involves sliding around on the lexical similarity dimension
to locate a match (e.g., "canine" against "dog").
Syntactic paraphrasing may also come into play (e.g., matching "Jupiter
has 18 moons" to "Jupiter's 18 moons"). Often both
are required ("How many moons does Jupiter have?" vs.
"Jupiter's 18 satellites").
"MindMelding relies on MindNet's path-finding and
lexical similarity routines. Briefly, paths between the least frequent
word in the input graph and other words directly connect to it are
identified. Along these paths, typically, are words that are found
to be similar to one of the endpoints (e.g. looking for paths between
'car' and 'top' might provide paths linked through 'vehicle' or
'hood'). These newly-identified words, which aren't simply similar
in meaning to the original words but, crucially, similar in this
particular lexical context, can now be used for matching if no structures
with the original words can be found. This process is iterated,
so that a number of contextually-similar words can be identified,"
says Dolan
Although the MindMelding algorithm relies on the type of
graph matching that is intractable (impossible) for the worst cases,
the wide variety of context and linguistic heuristics that the MT
system brings to bear on the matching problem prevents worst case
scenarios from occurring. Nonetheless, carrying out the match efficiently
is still a highly complex challenge.
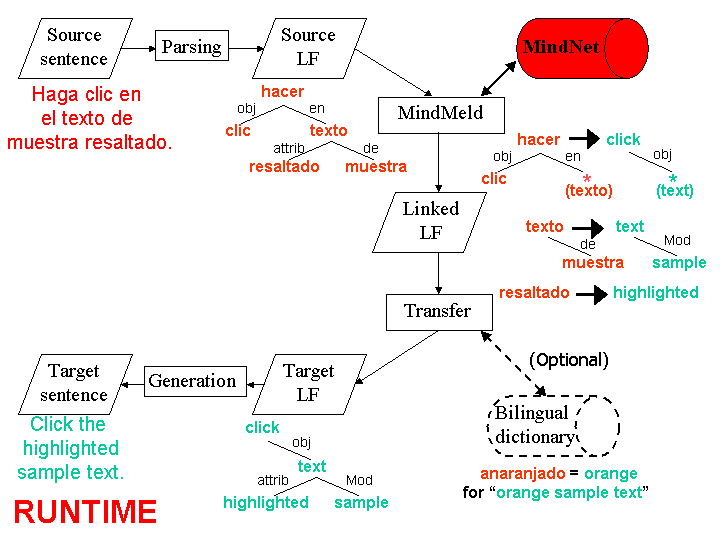
"We take the Logical Form and try to find
pieces
that match in the stored database mapping [of MindNet] and follow
those to the corresponding link on the English side.
Grab all those pieces and sort of Frankenstein
monster-like put them together into a Linked Logical Form. Right
now we are working on using language modeling techniques to smooth
out any differences that make that stitched together Logical Form
look non-native…using statistical techniques, we smooth out
any wrinkles that don't look like what an English Logical Form should
look like," says Dolan.
Once MindMeld has worked its magic, the
corresponding pieces of target LFs are stitched together to form
an English target LF, which is handed off to the Generation module.
"Provided we've done a good job of assembling a LF, the NLPWin's
generation component reliably maps that LF into a well-formed target-language
sentence," says Dolan. In the example shown in Figure 4, the
English string "Click the highlighted sample text" is
generated from the original Spanish input "Haga clic en el
texto de muestra resaltado."
At runtime, NLP Group's MT system translates
all the English text in the Microsoft Product Support
|
|
Intelligent Machine
Inc.
O'INCA
Design Framework for Windows
Integrated environment for development
of intelligent
adaptive systems.
|
FUZZY LOGIC
|
EASY TO USE
GUI &
DESIGN DOCUMENTATION
|
|
NEURAL NETWORK
|
SIMULATION
& DEBUGGING
|
|
USER-DEFINED
|
VALIDATION
& CODE
GENERATION
|
|
|
DECISION SUPPORT
& REASONING SYSTEMS
PROCESS CONTROL, PATTERN RECOGNITION
SYSTEM MODELING
|
|
$1,895 Enterprise
Version
|
$1,295 Educational
Version
|
|
Intelligent Machine,
Inc.
www.OINCA.net
Email info@oinca.net
Tel (408) 230-6441
|
|
Services Knowledge Base (KB) into Spanish, allowing
users to search the converted KB using Spanish queries. "As
articles are added or updated in English (which happens a couple
thousand times a week), they will be immediately (re-) translated
and posted to the Spanish KB. Occasionally, as the MT system improves,
the entire KB will be retranslated using newer versions of the MT
system. This will happen incrementally, so users should not experience
any down time," notes Richardson. To date, internal Microsoft
studies indicate a high level of satisfaction with the results obtained
using the translated Spanish PSS Knowledge Base.
|